Zeek Dictionary Comparison: Chained vs Clustered
details of chained dictionary vs clustered dictionary
Before the comparison, let’s compare the details of both dictionary structure details first.
chained dictionary
zeek deviates a little bit from the traditional chained hash table. It uses a dynamic array of initial size of 10 to replace the single link list. One of the major reasons is to avoid extra cost of pointer following. This improves lookup. On the other hand, as it leaves unused spaces in dynamic array, it uses a load factor of 3 to alleviate the space a bit. It causes hash map function to conflict on bucket at average of 3 on purpose.
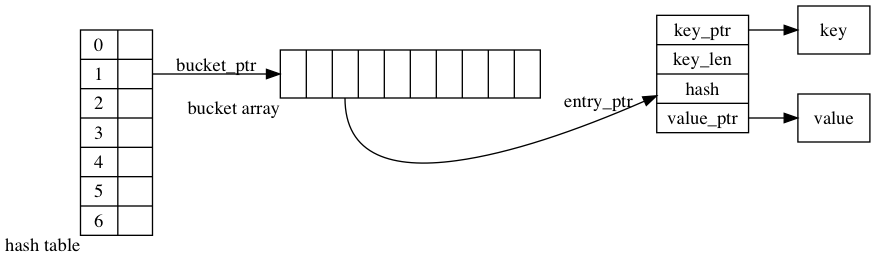
A successful lookup of key has to follow 3 pointers: bucket array -> entry_ptr -> key_ptr.
clustered dictionary
zeek clustered dictionary put the entries directly in the table. It removes 2 extra pointers in chained dictionary: bucket_ptr and entry_ptr. It also stores key directly in the table if the key size <= 8. So when the key is less than 8 bytes, it removes 3 extra pointers during lookup.
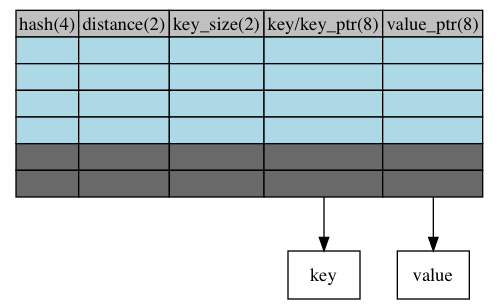
A succeessful lookup of key of size <= 8 will not follow any pointers. It follows key_ptr for key_size > 8.
Setup the environment for measurements
github.com/jasonlue/zeek.test.git contains all necessary files and scripts for measurements.
Install git and git large file storage (git-lfs)
apt install git git-lfs
clone zeek.test
git clone https://github.com/jasonlue/zeek.test.git
download pcap files & zeek executable from git-lfs for measurements.
warning: large files (more than 1G) from git lfs will be downloaded into your local directory.
git lfs fetch
Precompiled targets are under directory zeek
-
zeek, the original zeek. compiled by
./configure --enable-perftools -
zeek.stats, the original zeek with dict stats, under topic/jasonlue/dict_stats branch, compiled by
CXXFLAGS="-DUSE_DICT_STATS" ./configure --enable-perftools -
zeek.open, the new zeek with clustered dictionary, under topic/jasonlue/open_dict or topic/jasonlue/dict_stats branch, compiled by,
CXXFLAGS="-DUSE_OPEN_DICT" ./configure --enable-perftools -
zeek.open.stats, the new zeek with clustered dictionary as dict stats, under topic/jasonlue/dict_stats branch, compiled by
CXXFLAGS="-DUSE_OPEN_DICT -DUSE_DICT_STATS" ./configure --enable-perftools
Inputs
Uses 3 pcap files generated from smbtorture.cap through the procedure in post reprooduce-performance-issues-in-network-server-applications
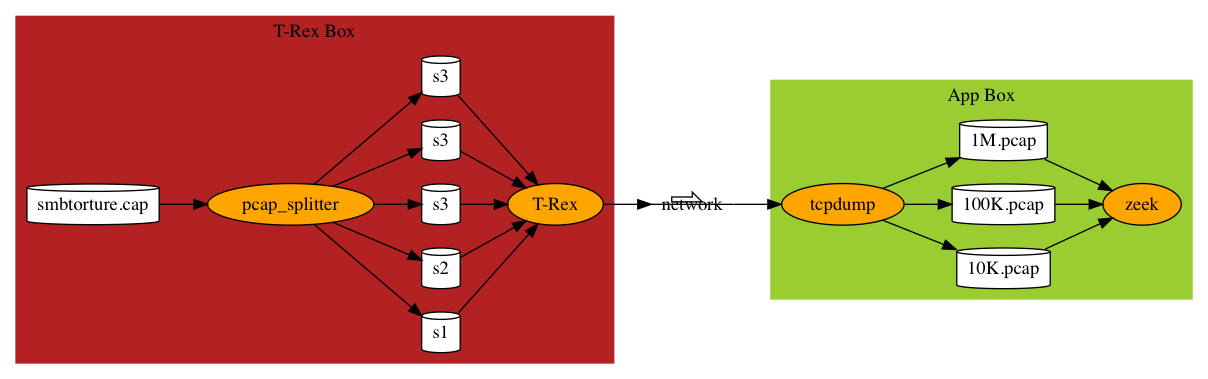
It measures zeek’s dictionary performance very effectively.
| name | description |
|---|---|
| 10K.pcap | 10,000 intensified smb packets |
| 100K.pcap | 100,000 intensified smb packets |
| 1M.pcap | 1,000,000 inteensified smb packets |
Dictionary Stats
Zeek and zeek scripts use dictionaries extensively. Most dictionaries are created by script and live with tcp/udp sessions. Tables and sets in broscripts are both dictionaries internally. Some scripts such as SMB protocol handler use up to 5 dictionaries.
cd ~/zeek.test/zeek
./zeek.stats -r ../pcap/10K.pcap
./zeek.stats -r ../pcap/100K.pcap
./zeek.stats -r ../pcap/1M.pcap
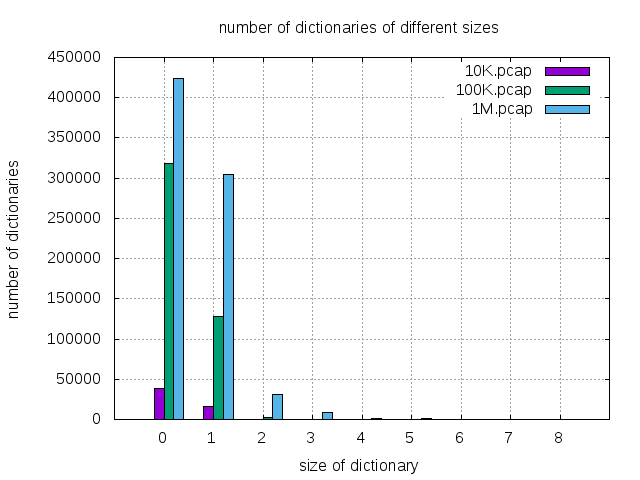
| dictionaries of max entries</br> |
10K.pcap | 100K.pcap | 1M.pcap | % |
|---|---|---|---|---|
| 0 | 37,991 | 318,045 | 424,433 | 55.09% |
| 1 | 15,576 | 128,566 | 303,966 | 39.45% |
| 2 | 201 | 1,896 | 31,444 | 4.08% |
| 3 | 26 | 30 | 8,227 | 1.07% |
| 4 | 17 | 18 | 775 | 0.10% |
| 5 | 14 | 13 | 957 | 0.12% |
| 6 | 12 | 22 | 319 | 0.04% |
| 7 | 6 | 6 | 27 | 0.00% |
| 8+ | 90 | 105 | 315 | 0.04% |
| total | 53,933 | 448,701 | 770,463 | 100.0% |
Memory
Memory consumed by a single dictionary
Use Tcp Connection dictionary with max of 147,695 keys as the test base.
measuring command:
cd ~/zeek.test/zeek
chained dictionary:
./zeek.stats -! ..//key/Connection.147695.key@1
./zeek.stats -! ..//key/Connection.147695.key@10
./zeek.stats -! ..//key/Connection.147695.key@100
./zeek.stats -! ..//key/Connection.147695.key@1000
./zeek.stats -! ..//key/Connection.147695.key@10000
./zeek.stats -! ..//key/Connection.147695.key@100000
clustered dictionary:
./zeek.open.stats -! ..//key/Connection.147695.key@1
./zeek.open.stats -! ..//key/Connection.147695.key@10
./zeek.open.stats -! ..//key/Connection.147695.key@100
./zeek.open.stats -! ..//key/Connection.147695.key@1000
./zeek.open.stats -! ..//key/Connection.147695.key@10000
./zeek.open.stats -! ..//key/Connection.147695.key@100000
| dictionary size | 1 | 10 | 100 | 1K | 10K | 100K |
|---|---|---|---|---|---|---|
| chained dict (bytes/entry) | 496 | 217 | 125 | 131 | 139 | 130 |
| clustered dict (bytes/entry) | 136 | 73 | 73 | 89 | 79 | 102 |
| faction of memory (%) | 27% | 34% | 58% | 68% | 57% | 78% |
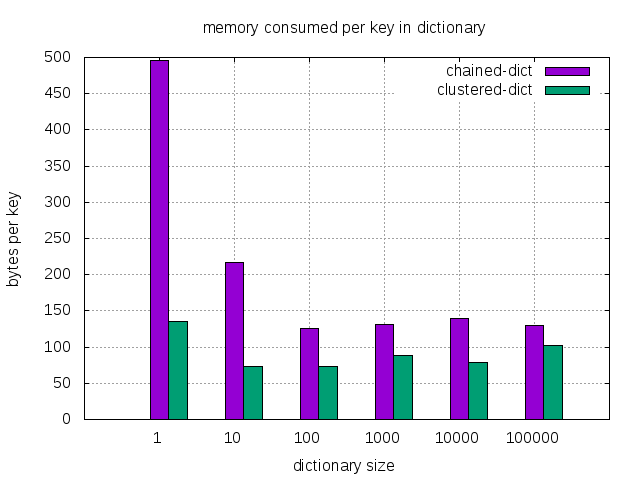
As we can see, Clustered dictionary uses a lot less memory especially when the dictionary size is small. Since more than 99% of the dictionaries in zeek are less than 8 in size. The memory improvement overall is estimated around 3x (34% of the chained dictionary) (when dictionary size is 10). More accurate measurement is in the next section.
cd ~/zeek.test/zeek
./zeek.stats -r ../pcap/10K.pcap
./zeek.stats -r ../pcap/100K.pcap
./zeek.stats -r ../pcap/1M.pcap
./zeek.open.stats -r ../pcap/10K.pcap
./zeek.open.stats -r ../pcap/100K.pcap
./zeek.open.stats -r ../pcap/1M.pcap
| malloc’d memory (M) | 10K.pcap | 100K.pcap | 1M.pcap |
|---|---|---|---|
| zeek with chained dict | 13 | 104 | 252 |
| zeek with clustered dict | 4 | 32 | 62 |
| fraction of memory(%) | 30% | 31% | 25% |
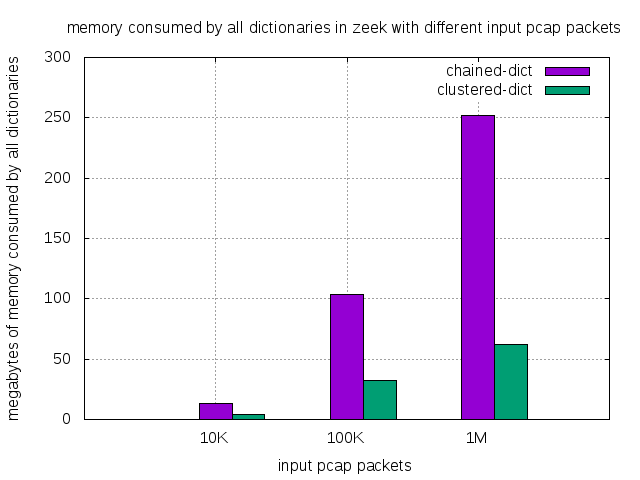
As it turns out, the memory consumed by all dictionaries is around 30% of the chained dictionary.
Overall application measurement
The memory saving effect on the overall application depends on how much memory in the application is consumed by the original chained dictionaries. The overall memory savings is pretty straight-forrward to measure, just by -Q flag provided by zeek.
./zeek -Qr ../pcap/10K.pcap
./zeek -Qr ../pcap/100K.pcap
./zeek -Qr ../pcap/1M.pcap
./zeek.open -Qr ../pcap/10K.pcap
./zeek.open -Qr ../pcap/100K.pcap
./zeek.open -Qr ../pcap/1M.pcap
| malloc’d memory (M) | 10K.pcap | 100K.pcap | 1M.pcap |
|---|---|---|---|
| zeek with chained dict | 144 | 816 | 1,672 |
| zeek with clustered dict | 135 | 749 | 1,499 |
| less memory(M) | 9 | 67 | 173 |
| less memory(%) | 6.25% | 8.21% | 10.35% |
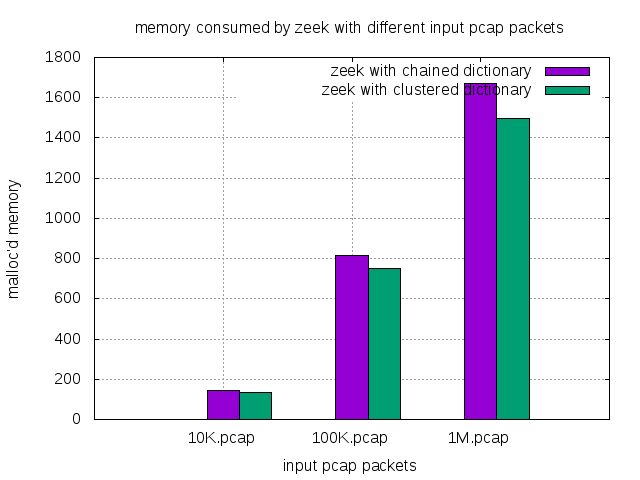
Time
Individual dictionary
To test the cache misses effect, the dictionary is not destroyed after each round. So the more rounds, the more memory is used during the test.
measure with different rounds
Accurate measument on time cost is harder than space because the time measured varies greatly from run to run based on the environment when it runs. The idea to make it more accurate is to run many rounds and then average them out to eliminate fluctuations due to environment.
But how many rounds is necessary to stablize the measurements? The criteria I used is to keep increasing the rounds until the numbers stablize but don’t deteriorate so as not to trigger cache miss effect discussed in the next section. Ususally 100,000 to 1 million measured operations can result in a stable number.
zeek.stats and zeek.open.stats adds a command line ! to accept a key file and indicates size of dictionary and how many rounds to run the measurement on.
cd ~/zeek.test/zeek
./zeek.stats -! ..//key/Connection.147695.key@100:1000
./zeek.stats -! ..//key/Connection.147695.key@100:10000
./zeek.stats -! ..//key/Connection.147695.key@100:100000
./zeek.stats -! ..//key/Connection.147695.key@100:200000
./zeek.stats -! ..//key/Connection.147695.key@100:4000000
./zeek.stats -! ..//key/Connection.147695.key@100:6000000
./zeek.stats -! ..//key/Connection.147695.key@100:8000000
clustered dictionary:
./zeek.open.stats -! ..//key/Connection.147695.key@100:1000
./zeek.open.stats -! ..//key/Connection.147695.key@100:10000
./zeek.open.stats -! ..//key/Connection.147695.key@100:100000
./zeek.open.stats -! ..//key/Connection.147695.key@100:200000
./zeek.open.stats -! ..//key/Connection.147695.key@100:4000000
./zeek.open.stats -! ..//key/Connection.147695.key@100:6000000
./zeek.open.stats -! ..//key/Connection.147695.key@100:8000000
When the rounds increase to certain level where cache miss is unavoidable, Chained dictionary performance deteriates.
| dict size of 100, running rounds | 1K | 10K | 100K | 200K | 400K | 600K | 800K |
|---|---|---|---|---|---|---|---|
| insert, chained (nanosec) | 106 | 118 | 105 | 108 | 152 | 186 | 256 |
| insert, clustered (nanosec) | 104 | 106 | 97 | 97 | 99 | 158 | 205 |
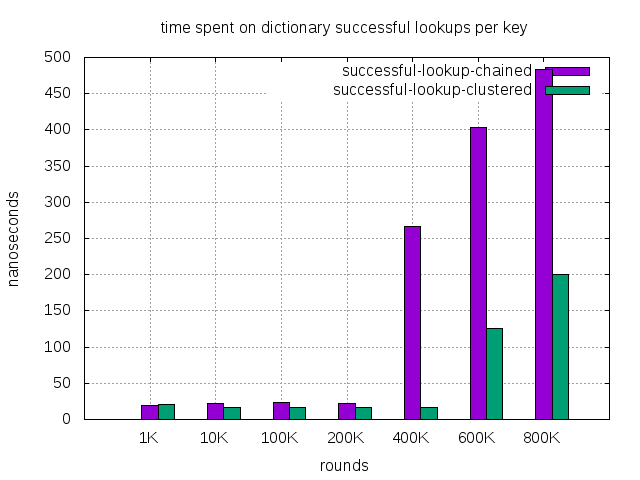
| successful lookup, chained (nanosec) | 19 | 22 | 24 | 22 | 267 | 404 | 484 |
| successful lookup, clustered (nanosec) | 21 | 16 | 17 | 16 | 17 | 126 | 200 |
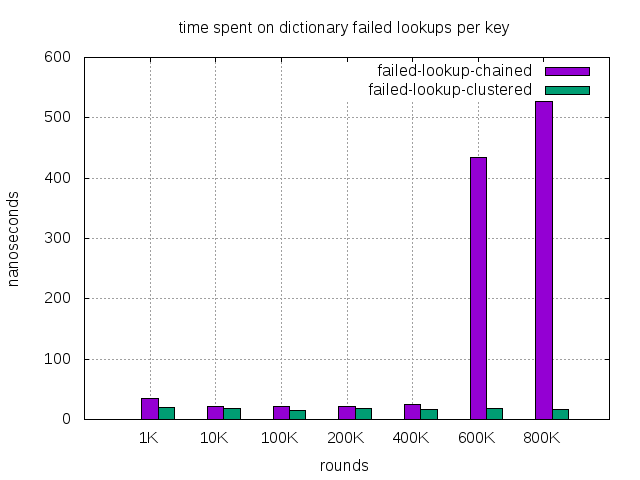
| failed lookup, chained (nanosec) | 34 | 21 | 22 | 22 | 25 | 435 | 527 |
| failed lookup, clustered (nanosec) | 20 | 19 | 15 | 18 | 16 | 18 | 17 |
| remove, chained (nanosec) | 24 | 23 | 24 | 24 | 26 | 486 | 594 |
| remove, clustered (nanosec) - | 21 | 18 | 17 | 17 | 18 | 19 | *17 |
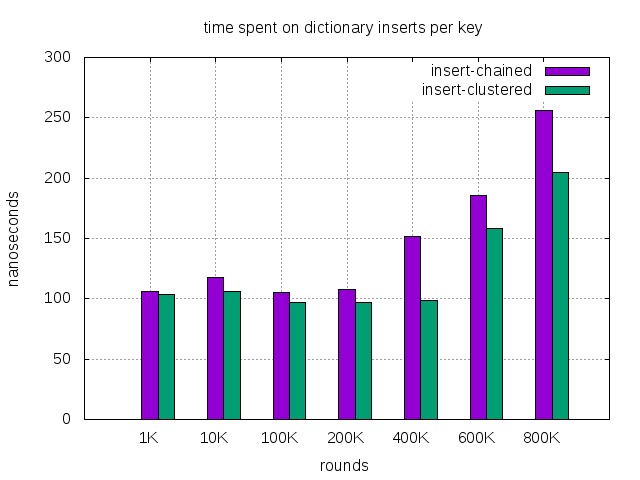
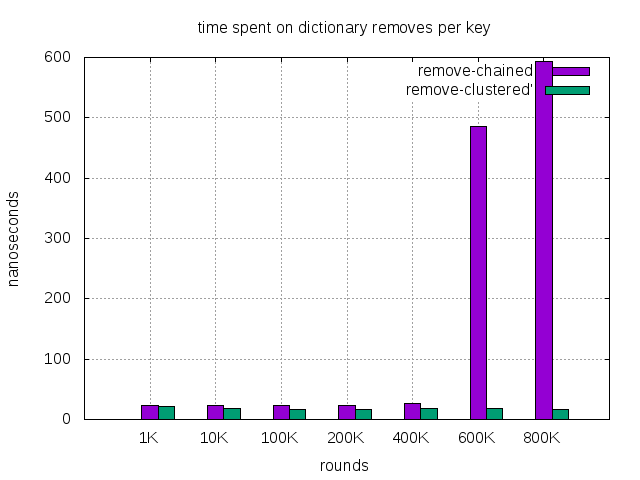
- remove, clustered holds up the normal performance without deteriorating requires some investigation and explanation.
cache miss effect displayed
When the rounds are less than 200K, the application still manages to keeps the majority part of data structure in cache.
When rounds increase to 400K, we have 400,000 dictionaries of size 100 at the maximum. Each item consumes 125 bytes in chained dictionary as measured in Memory section. we use 100 * 125 * 400K = 5G memory. When cache miss happens, the whole operation time is dominated by reading data from main memory and loading it into cache.
According to Computer Latency at a Human Scale, reading from main RAM is around 100 nanosecond. Chained dictionary successful lookup time’s increase from 22 to 267 nanoseconds likely caused by 2 L3 cache misses. Based on the algorithm of chained dictionary implementation in zeek, the key is a pointer to another address. The difference between successful lookups and unsuccessful lookups is that unsuccessful lookups finish probably on mismatched bucket, but successful lookups still need to compare keys.
So we see chained dictionary performance deteriorates greatly. The worst is the successful lookup. The time spent for it increases 10 folds from 22 nanosecs to 267 nanosecs. At the same time, clustered dictionary performance also decreases a bit, but it’s far better than chained dictionary. So clustered dictionary causes a lot less catch misses during lookup. The removal of 2 extra pointers is the major reason.
Clustered dictionary performance improvements
cd ~/zeek.test/zeek
./zeek.stats -! ../key/Connection.147695.key@1:1000000
./zeek.stats -! ../key/Connection.147695.key@10:10000
./zeek.stats -! ../key/Connection.147695.key@100:10000
./zeek.stats -! ../key/Connection.147695.key@1000:1000
./zeek.stats -! ../key/Connection.147695.key@10000:100
./zeek.stats -! ../key/Connection.147695.key@100000:30
./zeek.stats -! ../key/Connection.147695.key@-1:20
clustered dictionary:
cd ~/zeek.test/zeek
./zeek.open.stats -! ../key/Connection.147695.key@1:1000000
./zeek.open.stats -! ../key/Connection.147695.key@10:10000
./zeek.open.stats -! ../key/Connection.147695.key@100:10000
./zeek.open.stats -! ../key/Connection.147695.key@1000:1000
./zeek.open.stats -! ../key/Connection.147695.key@10000:100
./zeek.open.stats -! ../key/Connection.147695.key@100000:30
./zeek.open.stats -! ../key/Connection.147695.key@-1:20
| dictionary size | 1 | 10 | 100 | 1K | 10K | *100K | 147,695 |
|---|---|---|---|---|---|---|---|
| insert, chained (nanosec) | 186 | 135 | 105 | 151 | 277 | 440 | 599 |
| insert, clustered (nanosec) | 73 | 95 | 97 | 156 | 189 | 336 | 329 |
| insert, improvement(%) | 61% | 30% | 8% | — | 32% | 24% | 45% |
| successful lookup, chained (nanosec) | 21 | 28 | 22 | 33 | 61 | 185 | 243 |
| successful lookup, clustered (nanosec) | 12 | 13 | 19 | 33 | 52 | 211 | 175 |
| successful lookup, improvement(%) | 43% | 54% | 14% | — | 15% | -14% | 28% |
| failed lookup, chained (nanosec) | 24 | 25 | 23 | 28 | 48 | 75 | 100 |
| failed lookup, clustered (nanosec) | 14 | 14 | 18 | 28 | 37 | 73 | 62 |
| failed lookup, improvement(%) | 42% | 44% | 22% | — | 23% | 3% | 38% |
| remove, chained (nanosec) | 29 | 30 | 24 | 36 | 71 | 303 | 530 |
| remove, clustered (nanosec) | 15 | 16 | 19 | 36 | 57 | 274 | 309 |
| remove, clustered, improvement(%) | 48% | 47% | 21% | — | 20% | 10% | 42% |
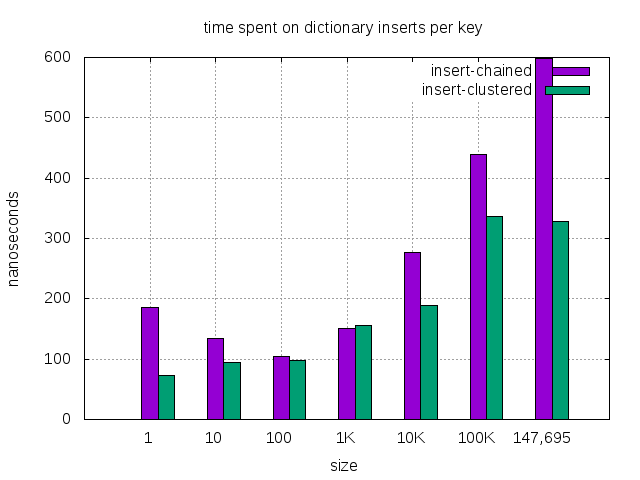
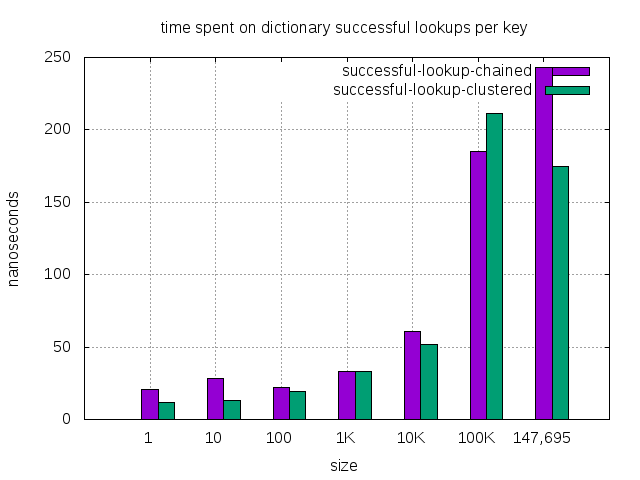
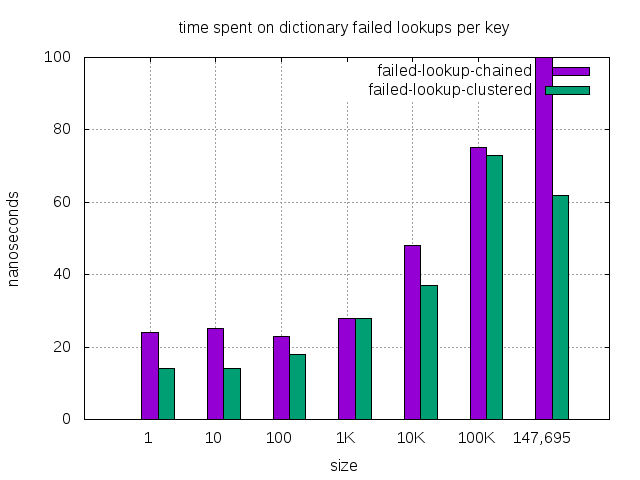
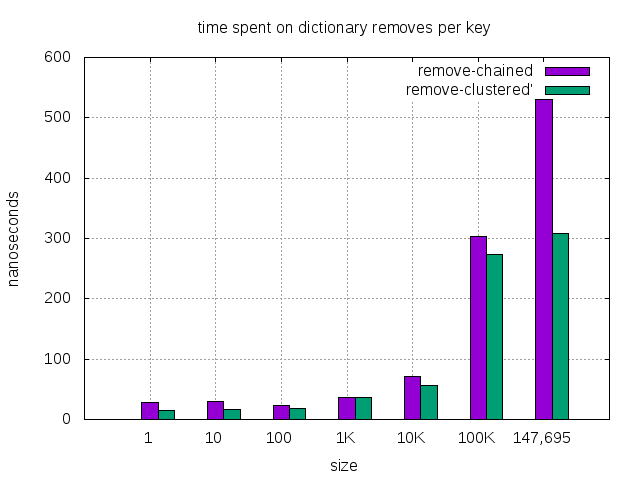
- Connections dictionary of 100K happens to be in mixed items mode. In mixed items, the lookup performance degrades a bit, which affects other operations too. It’s not a typical scenario during operation. Even in this transient period, clustered dictionary still performs better except the successful lookup.
The improvement is visible on smaller tables because in these tables the overall operation is fast. The chained dictionnary’s extra indirect pointer access dominates the whole operation.
The improvement is visible on large tables because in these tables the cache miss dominates the whole operation. Clustered dictionary has less cache misses than chanined dictionary thus it performs better.
Improvements over larger tables is less. Because 99.96% dictionaries in zeek have a size of 7 or less, clustered hashing improvements can be estimated by 30-50%.
processing time of all dictionaries
Didn’t find an easy way to measure.
Overall application processing time
Time is measured by running 12 rounds, dropping min and max and averaging the rest.
cd ~/zeek.test/zeek
./cmp-all.sh
| processing time (s) | 10K.pcap | 100K.pcap | 1M.pcap |
|---|---|---|---|
| zeek with chained dict | .25 | 2.13 | 13.23 |
| zeek with clustered dict | .24 | 2.02 | 12.41 |
| less time (s) | .01 | .11 | .82 |
| less time (%) | 4.00% | 5.16% | 6.20% |
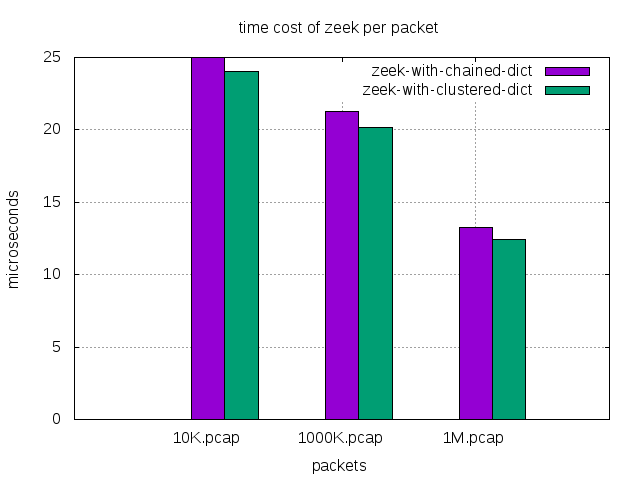
| processing time per packet(microsec) | 10K.pcap | 100K.pcap | 1M.pcap |
|---|---|---|---|
| zeek with chained dict | 25 | 21.3 | 13.23 |
| zeek with clustered dict | 24 | 20.2 | 12.41 |
References
reprooduce-performance-issues-in-network-server-applications